论文:Planting a SEED of Vision in Large Language Model
作者:Yuying Ge, Yixiao Ge, Ziyun Zeng, Xintao Wang, Ying Shan
发表:arXiv
本文提出了图片词元化 SEED 模块,它能赋予大型语言模型同时查看和绘图的能力。在本研究中,作者确定了 SEED 架构和训练的两个关键原则,可有效简化后续与 LLM 的衔接。(1)图像词元化应该独立于 2D 物理块位置,而是通过 1D 因果依赖性生成,表现出与 LLM 中从左到右自回归预测机制一致的内在相互依赖性。(2)图像标记应捕获与单词语义抽象程度一致的高级语义,并在标记器训练阶段针对区分性和重建进行优化。因此,现成的 LLM 能够通过高效的 LoRA 微调,并结合 SEED 模块可以实现图像到文本和文本到图像的生成。此版本的 SEED 仅使用 64 个 V100 GPU 和 500 万个公开可用的图像文本对,在 5.7 天内完成了训练。本文的研究强调了离散视觉标记在多功能多模态 LLM 中的巨大潜力以及合适的图片词元化模块的重要性。
先前工作
最近的研究进一步利用 LLM 的强大通用性来提高视觉理解或生成任务,统称为多模态 LLM (MLLM)。
BLIP 处理图片为 token 作为上下文,从而回答用户提出的问题。GILL 通过将其输出嵌入空间与预训练的 SD 模型对齐,赋予 LLM 图像生成能力。这两个任务在处理过程中有很大的相似度。在此基础上,存在将这两个任务进一步融合到一个框架内的可能性。
因此,作者做了一个大胆的假设,多模态能力出现的前提是文本和图像可以在统一的自回归 Transformer 中互换表示和处理。
SEED
提出的 SEED 是一种基于 VQVAE 的图像分词器,基于原图片生成具有一维因果依赖性的离散视觉码,这个离散视觉码具备视觉理解和生成任务所需的高级语义。该一维特征向量与 SD 的嵌入空间是对齐的,从而能够直接调用 SD decoder 生成图片。将第一步学习到的离散视觉标记视为新单词,并更新 LLM 的词汇表,再进行一定程度的微调,使得 LLM 理解这些新词汇。这样的做法可以让现有的 LLM 都能轻松兼容 SEED。
训练范式可以概括为三个阶段:视觉词元化模块训练、多模态预训练和多模态指令调整。虽然现有研究主要强调多模式训练(后两个阶段),但这项工作更关注视觉分词器(第一阶段)。
优秀的视觉分词器可以通过:简化视觉和单词标记之间的语义对齐,以及为多模态数据启用LLM的原始训练方法(即下一个词预测)来促进后续多模态训练,而无需针对视觉标记。将图像表示为一系列离散 ID 自然与 LLM 的自回归训练目标兼容。
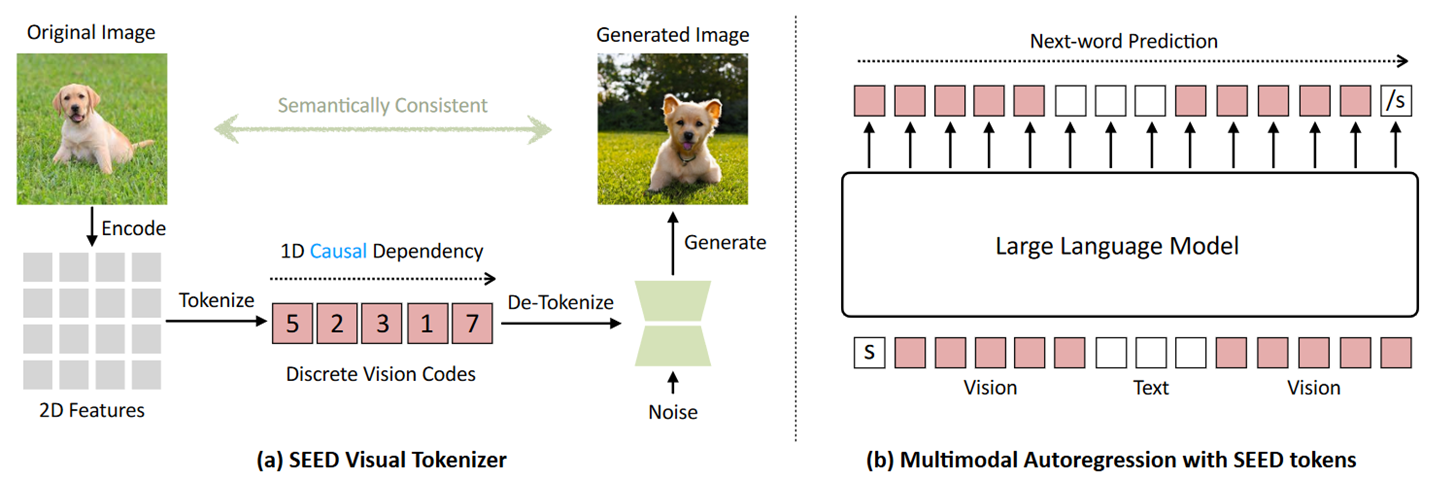
SEED 训练
模型包含 5 个组件,其中的 ViT 编码器和 UNet 解码器直接源自预训练的 BLIP-2 和 SD 模型,不参与训练。其余三个部分的参数都需要训练。训练过程可以分为以下三步。
Tokenize
该步目的是将图像表示为一系列离散Token。
使用来自 CC3M , Unsplash 和 COCO 数据集的 5M 图文对训练数据,基于图文对比损失优化 Causal Q-Former。对比损失函数中的正样本为图和图像的标题,负样本为同一个 batch 中的其他样本的标题。最大化正样本相似度,最小化负样本相似度。
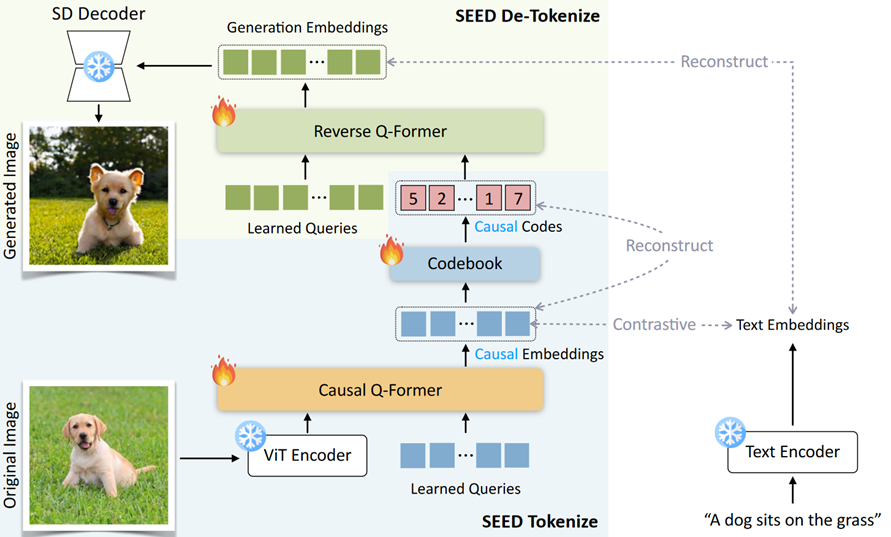
Visual Quantization
VQ Codebook 将每个 causal embedding 转换为离散的量化的 causal code。做法是在 Codebook 中查找每个 causal embedding 的最近邻并获得相应的 causal code。
codebook 训练:使用一个多层 Transformer 解码器,从离散的 causal code 重构连续的 causal embedding。目标函数是,最大化重构 causal embedding 和真实 causal embedding 之间的余弦相似度。
De-Tokenize
之前步骤得到了一串 code 包含了图片的信息,相当于一串没有实际意义的软文本,Reverse Q-Former 将学习到的 causal code 作为 cross attention 的 K V 输入,将 LQ 投影到 SD 的 Latent Space。最小化生成嵌入和 SD 文本特征之间的 MSE 损失。生成的嵌入可以输入 SD-UNet 来解码真实图像。
SEED 接入 LLM
训练好的 SEED 模块可以接入 LLM,可以是任意架构的 LLM,文中以 Decoder-Only 架构的 OPT 模型为例。
该过程涉及到两个训练任务:
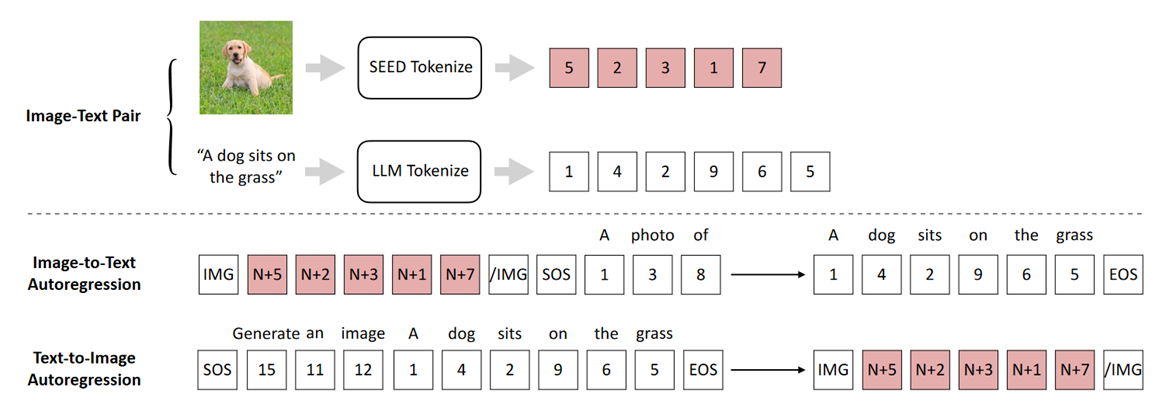
Image-to-Text Autoregression
将两个模态的数据都 token 化,图片使用 SEED ,文本使用 LLM。
将 causal codes 对其到 $\text{SEED-OPT}_{2.7B}$ 的嵌入空间。
使用 LoRA 微调 LLM,使 LLM 兼容新的词汇本。
Image-to-Text Autoregression
训练过程与上述任务相反。
训练过程不需要调用图片生成模型。
评估
Causal Embeddings 和 Causal Codes 定量评估
图文检索任务。
使用 BLIP-2 作为 Baseline。
COCO 和 Flickr30K 数据集。

Causal Visual Codes 重构能力定性评估
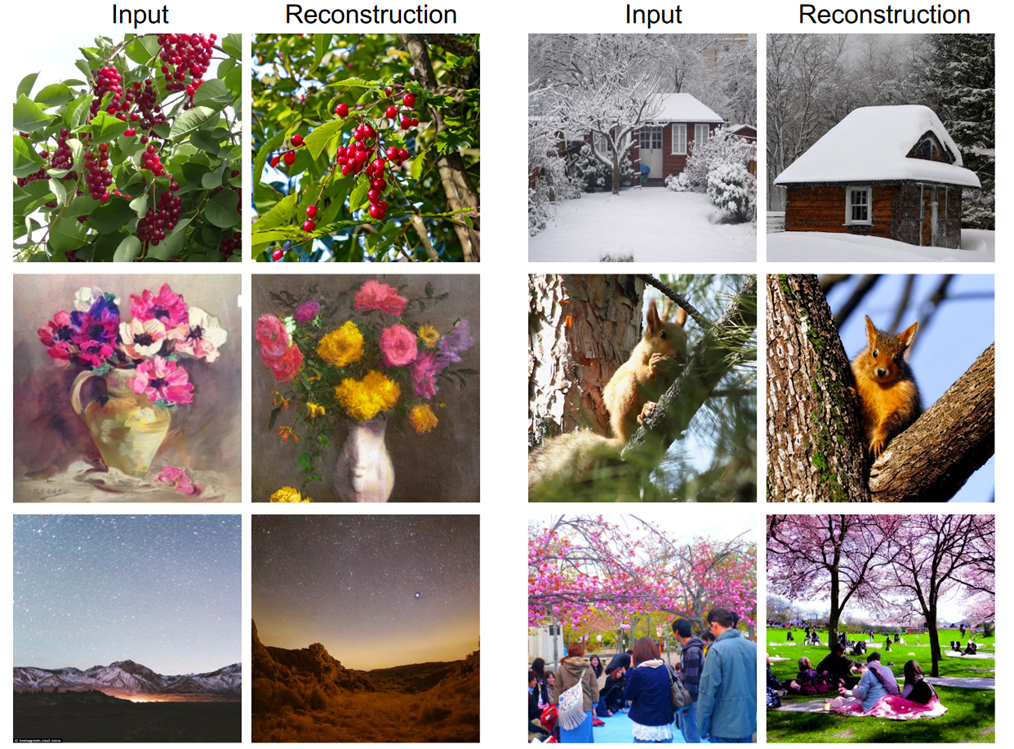
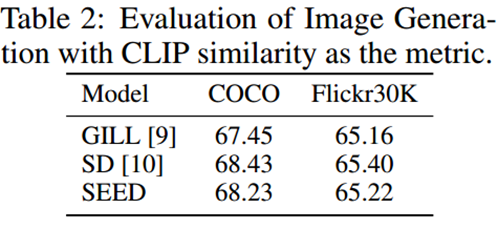
图片生成能力评估
SEED 首先将输入图像离散化为因果代码(32 个标记),并从 Reverse Q-Former 获得生成嵌入(77 个标记),并将其馈送到 SD-UNet 中以重建图像。
baseline 模型为 GILL 和 SD 。图像是根据输入图像的相应标题生成的。
CLIP相似度作为语义一致性基准的评估指标。

多模态理解能力评估

结论
- 通过高效的 LoRA 调优,结合 SEED 模块,现成的 LLM 能够执行图像到文本和文本到图像的生成。
- SEED 的训练过程仅使用 64 个 V100 GPU 基于 5M 个公开可用的图像-文本对,在 5.7 天内完成了训练。
- 缓解了 MLLM 中可能出现的灾难性遗忘问题。
Reference
[1] https://arxiv.org/pdf/2307.08041v2.pdf
[2] https://github.com/ailab-cvc/seed
[3] https://browse.arxiv.org/pdf/2301.12597v3.pdf
[4] https://openreview.net/pdf?id=YicbFdNTTy
[5] https://aclanthology.org/2022.acl-long.215/
✉️ zjuvis@cad.zju.edu.cn